目标定位
简而言之,目标检测的目的就是不仅仅要分别出物体是不是我们要识别的类型,还要做到定位出它所在位置。也就是我们所说的,classification with localization problem。其中也包括有多分类定位与简单检测。

图像分类

通常我们进行图片分类,所使用的方法就是卷积神经网络进行特征提取+Softmax分类的传统架构,当然其中不乏各种能提升效果的变体框架,如Inception、Res、VGG等等。
目标分类与目标定位
那么我们该怎么进行定位工作呢?
同样我们使用最暴力的想法的话,就是让我们训练的模型再额外输出四个值,分别对应图像中四个角的位置。
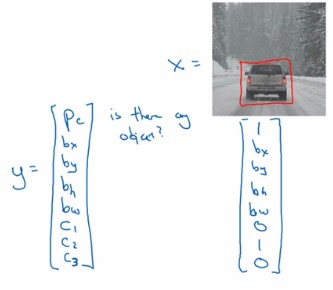
那我们该如何设置这一系列我们所需要的值为一个训练输出Y?

其中
- Pn代表是否具有物体
- Bx、By、Bh、Bw分别代表如果有物体,其范围如何
- C1,C2,C3 代表该物体属于哪一个类别
若不存在物体,则可以如此表示

最简单的损失函数可以如下设置:
虽然简化,但是确实你可以这么做,不一定非得在分类部分使用对数损失。
特征点检测
如果识别的图片存在某些特殊的你想获取的点,不妨让模型再最后输出部分再输出你所设置为特征点的坐标,同时进行训练。

类似的技术,可以实现AR增强现实与行为姿态检测的任务。
基于滑动窗口的目标检测
一般滑动窗口的方式
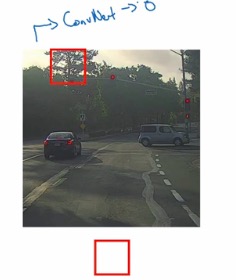
在实现基于滑动窗口的目标检测之前,我们还是要训练一个分类器的,然后在其之上进行滑动窗口的检测。

缺点:计算成本过大,特别是加上卷积之后。
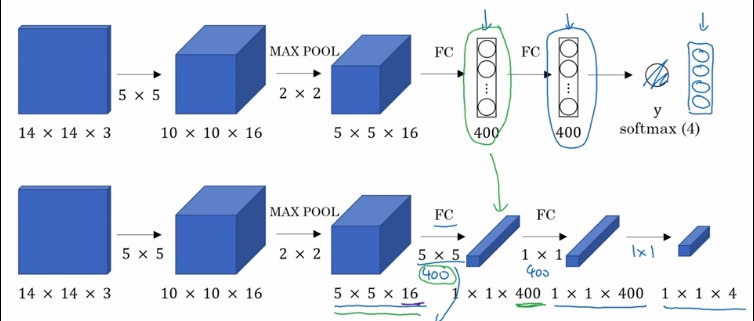
卷积的滑动窗口的实现
全连接到卷积的一点小改变,改变的目的就是为了让卷积之后的每一个区域都有一个softmax的结果:

其实,作为四张图片输入和卷积之后的四个区域是有一定关系的,卷积之后再切分可以共享很多计算,使得卷积滑动窗口计算成本大幅度降低。池化参数相当于步长。
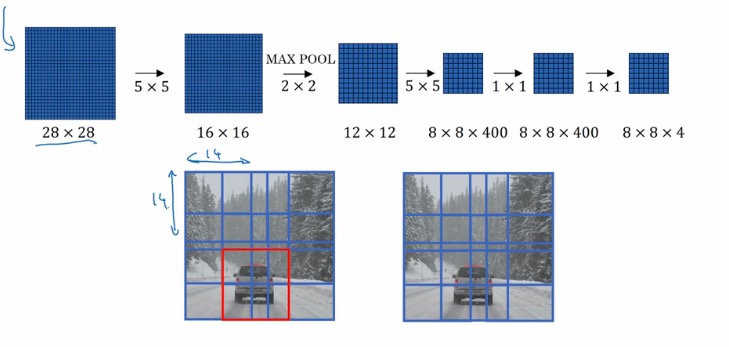
如果幸运的话,你就能够找到想要的区域。而且只用进行一次卷积操作。
Bounding Box 预测
YOLO算法初探
将整张图片分为多个部分,比如在这里是九个部分,九个部分都是用上面介绍的图像检测算法。
这样我们会得到一个3X3X8的输出,这就是我们最终用来训练的东西。
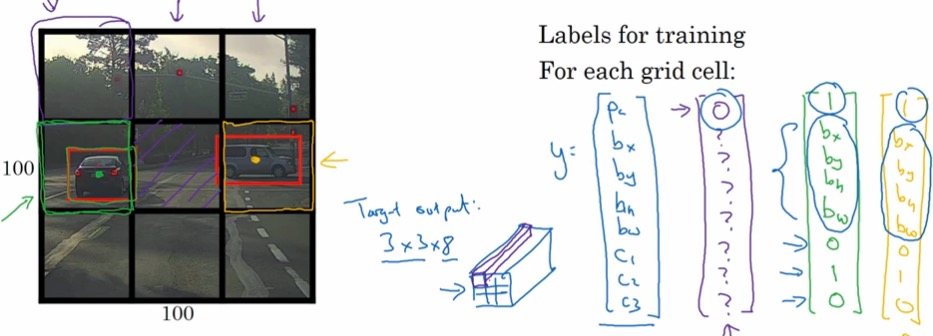
当然在真实使用的时候,网格可能精细得多。
好处在于,九个格子都是共用一套神经网络,所以训练起来方便很多!
另外还提到如何确定某个格子内框框的表示问题,在这儿只是给出一个行之有效的方式。

左上和右下分别表示为(0,0)、(1,1),中间橙色点为X,Y的坐标定位,H、W则使用比例尺表示。
交并比(IoU)
如何判断网络运行得好还是坏呢,那就是交并比函数。
简单来说就是交集和并集的比率。一般约定0.5为一个能够接受的值。

非极大值抑制(Nms)
在19X19的网格网络中,很多区域都会认为他们自己内部包含了我们要检测的目标物,那么我们如何使用这些标签呢,如何确定一个重点?

举个简单例子,在下面这块区域中,有多个重叠,概率值比较高的区域判定其中包含我们需要检测的物体,我们其中值最大的选用其范围,所有和这个最大边界框有很高iou值的其他边界框都会被抑制,如果我们直接删除这些边界框,就得到了另一个结果。
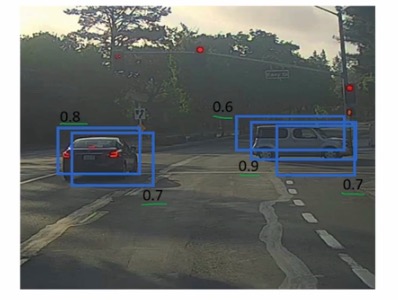

算法细节上,我们通过通过得到的19X19X5(只做汽车识别的话)的区域给定一个概率阈值,然后判断剩下区域的概率值和IOU值进行遍历过滤,最终会得到我们想要的结果的。
Anchor Boxes
如果想检测出多个不同的物体,我们就需要使用Anchor Box这个概念。
比如现在我们有这样一个3X3的图片分割。如果两个我们要检测的物体重叠的太厉害,根据我们上面定义的输出其实是无法解决的。
通过anchor box 我们将输出分别绑定了不同的anchor box,输出不同的值。

具体而言,之前我们输出的八个值,比如该图我们得到的结果会是3X3X8的样子。而现在我们要根据不同类别形状对应按个anchor box的IOU值更高,将其分配到不同的区域之中去。这样我们得到的就是3X3X16的输出。举个例子:

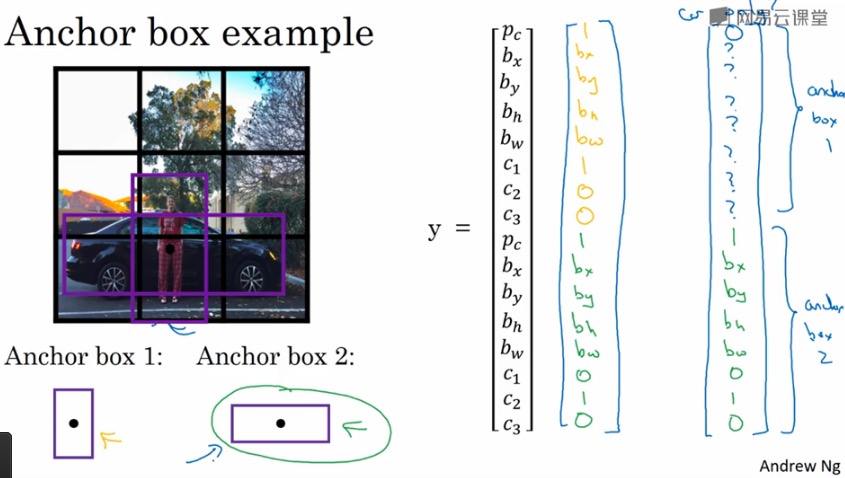
当然有些情况还是处理不好,比如两个检测的物体还是重叠的……那场面就很很尴尬,需要引入其他方式来解决这个问题。
anchor box 很多人都是手工来定义的,YOLO中其实给了比较好的做法。
当然也有自动选择anchor box的算法。
YOLO
现在我们要将上面所涉及的所有东西组合成我们要使用的YOLO算法。
依旧老生常谈,3X3转化为3X3X2X8,在使用两个anchor box+3个类别需要识别的情况下。
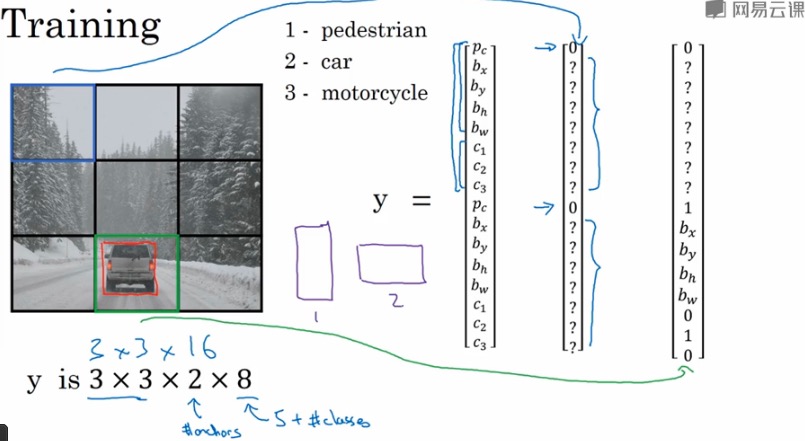
然后运行nms的过程。首先得到识别结果,然后抛弃概率值低的,最后进行非极大值抑制



老铁,没毛病!
候选区域(Region Proposal)
非常具有影响力的研究,之后可能会单独写博文
R-CNN
克服了传统滑动窗口在没有必要检测区域浪费时间的问题,只选择某些window。
思想是运行图像分割技术,获得色块,然后在不同色块上运行CNN。

R-CNN演变史
R-CNN
用某些算法获得候选区域,然后对每个候选区域跑一下分类器,每个区域输出一个标签,并输出一个边界框。R-CNN并不会完全信任这个边界框,它自己也会输出一个边界框。获得更加精确的结果。
缺点就是,也很慢……
Fast-RCNN
使用了卷积滑动,就如之前所说,卷积之后的滑动窗口进行R-CNN。
缺点就是,还是不够快……因为获取候选区域的部分还是很缓慢。
Faster-RCNN
卷积网络而不是传统分割方法获取候选区域。
他们都比YOLO要慢