生成对抗网络(Generative Adversarial Network)
目录:
生成对抗网络介绍
简单的生成对抗网络
深度生成对抗网络
条件生成对抗网络
INFO生成对抗网络
Wasserstein GAN
实例解析:deepcolor
生成对抗网络介绍
基本介绍
非监督式学习
神经网络相互博弈
扬·古德费洛2014年提出
组成部分
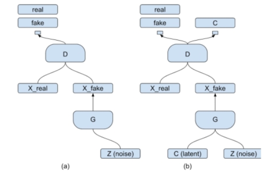
生成网络:从潜在空间(latent space)中随机采样作为输入,其输出结果需要尽量模仿训练集中的真实样本。
判别网络:判别网络的输入为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。
生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
用途
图片生成、视频生成、三维物体模型、甚至文本生成等。
实现方式与数学原理
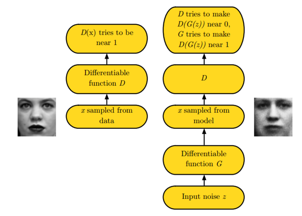
生成模型G与判别模型D
生成模型G用于从最初给定的高斯随机噪声Z映射到真实数据空间。
判别模型D用于判断输入是否为真实数据,返回{0,1}结果
生成模型G要不断欺骗判别模型D,而判别模型D要不断学习防止被欺骗。则目标函数可以表示为:
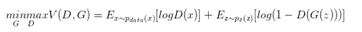
具体细化分解为:
定义判别模型,将真实样本全部判别为1,将生成样本全部判别为0,将两个问题都转为最大化问题,则有


我们将两者相加,构成目标函数
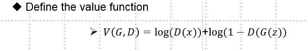
为了保证判别模型最优,我们需要将V(G,D)最大化

在保证了判别模型最优的情况下,我们将调节生成模型,使得生成模型让最优判别模型效果最差,则有
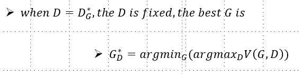
最终我们获得了目标函数
学习的过程中还是使用梯度下降
证明V(D,G)有最优判别模型:
那么最优的判别模型就是:
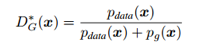
GAN最终的目的是,得到生成模型可以生成非常逼真的数据,也就是说和真实数据分布一样的数据,此时鉴别模型的输出为1/2 = 0.5
我们也可以证明生存模型是存在的:
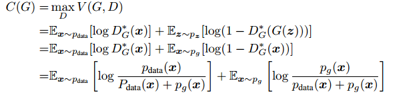
充分性:
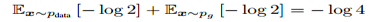
必要性:



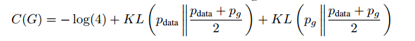
KL散度永远大于等于0,可以知道目标函数最终最优值为-log4
举例:模拟高斯分布
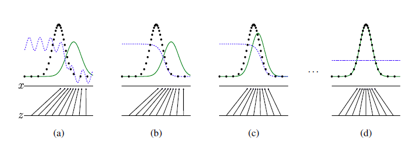
其中,蓝线为判别分界,黑点为真实数据,绿线为生成模型,整个高斯分布的学习过程,就是先优化判别模型,使得蓝色判别分界最优化,再优化生成模型,使得生成模型和真实高斯分布能够迷惑判别模型,判别结果为0.5(即完全迷惑)。
简单的生成对抗网络
简单GAN模型结构
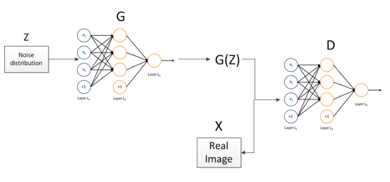
例如,该结构使用简单的神经网络结构,生成器G方面使用全连接,输入为随机初始化的Z,输出G(Z)为通过生成器生成的图片数据。将生成图片与真实图片再放入一个神经网络结构进行判别,判断来自X的可能性,是一个常量。
简单GAN模型效果
在不同的实验中,对模型进行了不同的更改,也达到了一定的效果,在GOODFLOW的论文中采用了不同的数据集和不同的模型,获得了如下生成效果


深度生成对抗网络
深度生成对抗网络,也就是常说的DCGAN,深度卷积生成对抗网络,在简单生成对抗网络的基础上加入的卷积层,使得生成对抗神经网络对图像等数据的生成效果更加优秀。
DCGAN模型框架
整个生成模型部分结构如下,它是由最初随机生成的Z,通过多次de-convolution操作,生成成为64x64x3的图片。
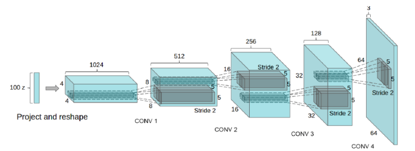
De-convolution是卷积的逆向操作,常用的方法为transport-convolution,上采样卷积,但上采样卷积由不能算真正的反卷积,因为它只能还原大小,无法还原其真实值。
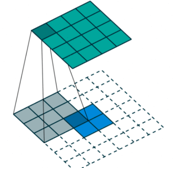
蓝色2x2区域为输入,通过3x3的反卷积操作,得到了上面的4x4的区域。
DCGAN模型在LSUN(卧室图片集)上效果

DCGAN模型实现时的技术细节
(1)D Leaky-relu激活函数,G relu 激活函数。
(2)使用batch_normalization。
(3)没有pooling层,使用步长为2的卷积。
(4)学习率很小,rate=0.0002。
启发
DCGAN生成了图片之后,在D模型中转化为了特征向量后同样能够用来做分类等传统操作吗?
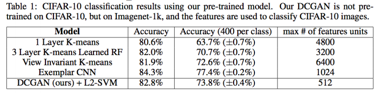
有人(原论文)将DCGAN+SVM用于图片分类,即将DCGAN中生成的图片同样进行特征提取,输入SVM中进行分类,效果还不错。
DCGAN模型中随机初始化的噪声Z对生成结果的影响
通过改变Z某一维度的值,生成图片会发生明显并含有规律的变化,这证明了Z噪声和词向量有一定的相似之处,在训练完GAN模型之后,能用来表达图片的特征。
改变Z某一维度值后生成的图片发生的变化:
在下图中,我们将戴眼镜男子的随机信号设定为Z1(可以将所有不戴眼镜男子的Z值作平均操作,后同),不戴眼镜的男子随机信号设定为Z2,不戴眼镜的女子随机信号设定为Z3,最后得到的Z4 = Z1 –Z2 + Z3。

更多特征研究,如方向插值等……

条件生成对抗网络
条件生成对抗模型(cGAN)模型
意在通过给定一些其他label信息,引导生成模型的输出。与之前我们所看到的不同的是,输入部分不仅仅是一个简单的随机噪声Z,又多了一个标准的label向量Y。
即训练过程的输入为:随机噪声信息+约束条件特征表示。
目标函数更新为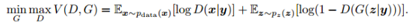
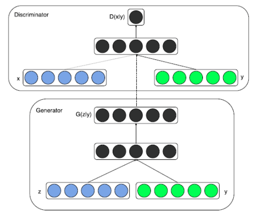
举个例子
使用标签类别作为条件变量y,对编码成one-hot向量的MNIST图像进行条件对抗网络的训练。
效果如下,左为有条件的,右为无条件的。


若我们给定的Y是文字,则模型可以如下表示:
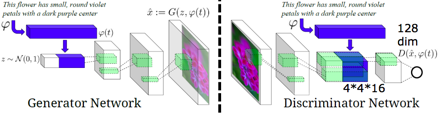
如图所示,生成模型将句子转为特征后拼接于在Z之后进行传统的GAN DCGAN操作,生成图片,判别模型将图片特征抽取后再加入句子特征进行判别。

若我们给定的Y是文字+位置,则模型可以如下表示:
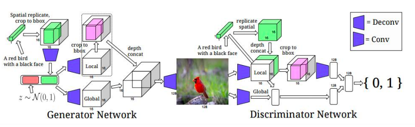
如图所示,生成模型将句子转为特征后拼接于在Z之后,分两个模块分别加入全局信息和局部位置信息,组合后进行传统的GAN DCGAN操作,生成图片,判别模型将图片特征抽取后再加入句子特征、全局特征、位置信息等,综合进行判别。

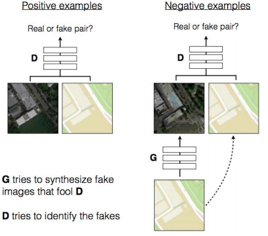
若我们给定的Y是一张图片,即我们模型的输入会是一个图片对,则模型可以如下表示:
目标函数则变化为:
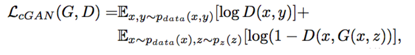
效果如下:

Info GAN
InfoGAN的基本思想
同样也是在输入部分进行更改,输入噪声向量改变为两个部分:
(1)Z,噪声向量,随机初始化。
(2)C,语义向量,随机初始化。定义一系列的相互独立的潜在语义变量C1、C2……
这个语义变量C,是用来提供信息正则化约束项的,即潜在变量C与生成样本G(z,c)的互信息量应该比较大,即I(c;G(z,c))应该较大。
改进后的目标函数:
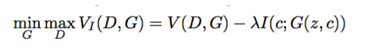
实现方式:

最终达到的效果是,通过改变具有物理意义的C,可以用于生成不同风格的特定图片。

数学证明:
互信息:
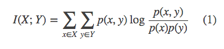
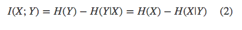
条件熵:
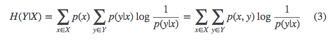
利用贝叶斯公式:
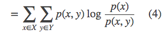
I(X;Y)根据对数函数可分解为:
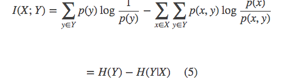

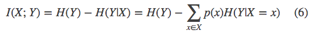
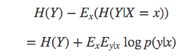
引入一个估计分布q(y|x) :
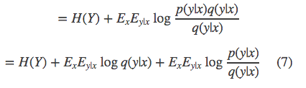

W GAN
W GAN 简介
从2014年Ian Goodfellow提出以来,GAN就存在着训练困难、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。从那时起,很多论文都在尝试解决,但是效果不尽人意,比如最有名的一个改进DCGAN依靠的是对判别器和生成器的架构进行实验枚举,最终找到一组比较好的网络架构设置,但是实际上是治标不治本,没有彻底解决问题。而今天的主角Wasserstein GAN(下面简称WGAN)成功地做到了以下爆炸性的几点:
贡献
彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
基本解决了collapse mode的问题,确保了生成样本的多样性
训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高
以上一切好处不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
改进
改进后相比原始GAN的算法实现流程却只改了四点:
判别器最后一层去掉sigmoid
生成器和判别器的loss不取log
每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
WGAN如果用类似DCGAN架构,生成图片的效果与DCGAN差不多:

WGAN不用DCGAN各种特殊的架构设计也能做到不错的效果,比如如果大家一起拿掉Batch Normalization的话,DCGAN就崩了:

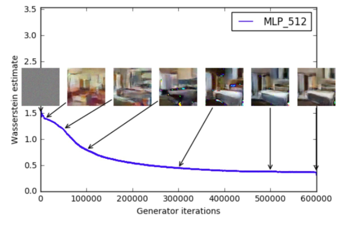
如果WGAN和原始GAN都使用多层全连接网络(MLP),不用CNN,WGAN质量会变差些,但是原始GAN不仅质量变得更差,而且还出现了collapse mode,即多样性不足:

https://zhuanlan.zhihu.com/p/25071913 这里的公式推导太长了……
实例解析:DeepColor
Deep color
https://github.com/kvfrans/deepcolor deepcolor 补全色彩,条件GAN。
需要改源码才能运行!!
我的运行结果:


https://github.com/YadiraF/GAN 绝大部分GAN的简单代码,可以用来讲解流程。没跑过。